Foundations Of AI Security 2
MITRE ATLAS
MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems) and the AI Risk Management Framework (AI RMF) are both initiatives aimed at addressing the security and risk management challenges posed by AI systems, but they focus on different aspects and serve complementary roles.
Like MITRE ATT&CK®, ATLAS was developed by MITRE to improve cybersecurity, yet they serve distinct areas within the security domain. ATLAS focuses on protecting Artificial Intelligence (AI) systems from unique threats like data tampering and tricking AI into making wrong decisions. It gives detailed advice on how to spot and stop attacks specifically aimed at AI technologies. On the other hand, ATT&CK covers a broader range of cyber threats that can hit any organization’s IT systems. It talks about common cyber attacks, such as viruses and phishing scams, and provides tips that can help any company improve its cybersecurity.
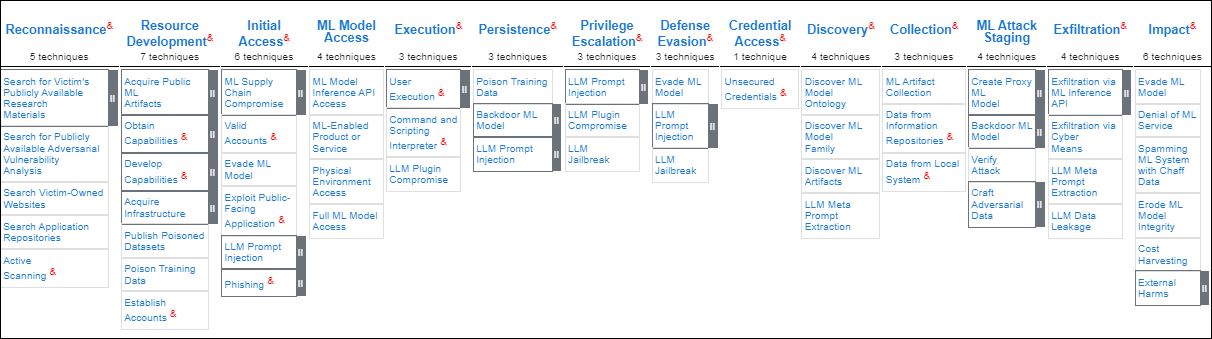
ATLAS consists of 14 tactics, all with a range of techniques that apply to them. Several of the tactics utilized in ATLAS will be familiar if you have experience with ATT&CK. Those tactics are:
Reconnaissance
Adversaries engage in reconnaissance to collect information about a target’s machine learning (ML) system, which helps them prepare for future attacks. This process involves both active and passive methods to gather data on an organization’s ML technologies and projects. The insights obtained can guide adversaries in acquiring ML artifacts related to the target, attacking the target’s ML applications, customizing assaults for the target’s specific models, or informing further reconnaissance activities.
Resource Development
Adversaries develop resources to support their operations, which includes creating, buying, or stealing assets like machine learning artifacts, infrastructure, accounts, or capabilities. These resources assist in further stages of an attack, such as preparing for a machine learning attack.
For instance, an attacker could create a fake social media account to gather data on an organization’s employees. This account could then be used to launch spear-phishing attacks aimed at obtaining access to the organization’s machine learning systems.
Initial Access
The adversary’s goal is to infiltrate an AI system during initial access. This can be accomplished through a range of techniques.
For example, in a carefully orchestrated cyber attack, attackers aimed to circumvent a facial recognition system for initial access. Their plan involved acquiring inexpensive mobile phones as the operation’s hardware foundation. They customized these devices with special Android ROMs and a virtual camera app, setting the stage for their attack. The attackers then procured software capable of transforming static photographs into dynamic videos that simulate real human gestures, such as blinking, to lend authenticity to the images. By purchasing personal data and high-definition facial photographs from the dark web, they created digital profiles mimicking the targeted victim. Leveraging the virtual camera application, these animated videos were presented to the machine learning-based facial recognition service during the verification process. This sophisticated approach successfully deceived the facial recognition system, allowing the attackers to impersonate the victim and gain unauthorized access to their tax information.
ML Model Access
Adversaries aim to obtain some level of access to a machine learning model, which can range from full insight into the model’s internal workings to merely interacting with the data input mechanisms. Gaining access allows them to gather information, tailor attacks, or feed specific data into the model.
For instance, an attacker could target a publicly available ML model provided through an API or manipulate a service that incorporates ML, influencing the model’s outputs to their advantage. A practical example of this could involve a hacker accessing a voice recognition system used in virtual assistants. By understanding how the system processes voice commands, the attacker could input malicious commands or exploit vulnerabilities, affecting the assistant’s behavior or accessing restricted information.
Execution
Adversaries use execution techniques to run harmful code on both local and remote systems by embedding it within machine learning artifacts or software.
For example, an attacker could insert a malicious script into a machine learning model’s code, which is then executed when the model processes data, giving the attacker unauthorized access to the system’s data or operations.
Persistence
Adversaries aim to keep their unauthorized access to a system, even through restarts or security updates, by using persistence techniques involving machine learning artifacts or software.
As an example, an attacker might modify a machine learning model or its training data to create a backdoor, ensuring they can regain access anytime without detection.
Privilege Escalation
Adversaries aim to gain higher-level permissions to achieve their objectives, such as accessing sensitive data or systems. Privilege Escalation involves exploiting system weaknesses, misconfigurations, or vulnerabilities to obtain elevated permissions like SYSTEM/root level, local administrator, or specific user accounts with admin-like access.
For instance, an adversary might exploit a vulnerability to gain local administrator rights, allowing them to install malicious software or access restricted areas. This process often works in tandem with Persistence techniques, where the methods used to maintain access can also provide higher privileges.
Defense Evasion
Adversaries employ Defense Evasion strategies to avoid detection by machine learning-enabled security systems, like malware detectors. These techniques are designed to slip past AI-driven safeguards, ensuring their malicious activities remain unnoticed.
As an example, an attacker might modify the code of their malware to evade detection algorithms, allowing them to infiltrate a network without triggering any alerts.
Credential Access
Adversaries engage in Credential Access to acquire usernames and passwords through methods such as keylogging or credential dumping. This enables them to access systems discreetly and create additional accounts for further malicious activities.
For instance, an attacker might use a phishing email to trick a user into entering their login details on a fake webpage, thereby capturing those credentials for unauthorized access.
Discovery
Adversaries engage in Discovery to learn about a system and its network. This process helps them understand the environment, identify what they control, and find potential advantages for their objectives. Often, they use the system’s own tools for this post-compromise reconnaissance.
For example, the attacker might use scripts or automated tools to scan for accessible machine learning APIs or data repositories. Upon discovering an open API used for machine learning model predictions, the adversary assesses it for vulnerabilities, such as weak authentication mechanisms, which could then be exploited to inject malicious data, access sensitive model information, or manipulate model behavior.
Collection
An adversary aims to collect machine learning (ML) artifacts and relevant data to further their goals. This process involves using various methods to compile information that aids in achieving the adversary’s objectives, such as theft of ML artifacts or preparation for future attacks. Key targets for collection include software repositories, model repositories, and data storage systems.
As an example, an attacker might infiltrate a cloud storage service used by a company to store ML models and training data. By accessing this repository, the attacker collects sensitive ML models and datasets, which could be used to understand the company’s ML capabilities, replicate the models for malicious purposes, or identify vulnerabilities for further exploitation.
ML Attack Staging
An adversary uses their understanding and access to a target system to customize their attack specifically for that system. This involves preparing various strategies like creating similar models for practice (proxy models), tampering with the target model’s data (poisoning), or designing misleading inputs (adversarial data) to deceive the target model. These preparations, often done before the attack and without online detection, pave the way for the main assault aimed at compromising the ML model.
For instance, an attacker targeting a bank’s fraud detection ML system might first develop a proxy model that mimics the bank’s system. By understanding how the bank’s model works, the attacker can craft financial transactions that appear normal to the bank’s ML system but are actually fraudulent, effectively bypassing the fraud detection mechanisms.
Exfiltration
An adversary aims to steal valuable machine learning artifacts or data from a system. This process, known as Exfiltration, involves methods to secretly remove data from a network. The stolen data, often containing sensitive intellectual property or information critical for planning future attacks, is typically transmitted via a control channel established by the adversary. They may also use alternative methods for data transfer, sometimes imposing size limits to avoid detection.
Impact
An adversary aims to disrupt or damage your AI systems and data, affecting their availability, integrity, or credibility. This could involve actions like tampering with or destroying data to hinder business operations or sway them in the attacker’s favor. While some processes may appear normal, they could have been subtly altered to serve the adversary’s objectives, ultimately enabling them to achieve their goals or mask a breach of data confidentiality.
1) Reconnaissance :
- Search for Victim’s Publicly Available Research Materials
- Journals and Conference Proceedings
- Pre-Print Repositories
- Technical Blogs
- Search for Publicly Available Adversarial Vulnerability Analysis
- Search Victim-Owned Websites
- Search Application Repositories
- Active Scanning
2) Resource Development :
- Acquire Public ML Artifacts
- Obtain Capabilities
- Develop Capabilities
- Acquire infrastructure
- Publish Poisoned Datasets
- Poison Training Data
- Establish Accounts
3) Initial Access :
- ML Supply Chain Compromise :
- GPU Hardware
- ML Software
- Data
- Model
- Valid Accounts
- Evade ML Model
- Exploit Public Facing Application
- LLM Prompt Injection
- Direct - An attacker directly inputs harmful prompts into a large language model (LLM) to either gain access to the system or misuse the LLM, such as creating harmful content.
- Indirect - An attacker indirectly inputs harmful prompts into a large language model (LLM) by using separate data sources like text or multimedia from databases or websites. These prompts can be hidden or disguised, allowing the attacker to gain access to the system or target an unsuspecting user.
- Phishing
4) ML Model Access :
The ML Model Access tactic is a grouping of 4 techniques in which The attacker is trying to get some control over a machine learning model.
- ML Model Inference API Access
- ML-Enabled Product or Service
- Physical Environment Access
- And, Full ML Model Access
5) Execution :
A grouping of techniques in which Attackers try to execute harmful code hidden within machine learning artifacts or software.
- User Execution
- Unsafe ML Artifacts
- Command and Scripting Interpreter
- LLM Plugin Compromise
6) Persistence :
- Poison Training Data
- Backdoor ML Model
- Poison ML Model
- Inject Payload
- LLM Prompt Injection
7) Privilege Escalation :
Attackers aim to obtain higher-level permissions to achieve their goals within a system or network.
- LLM Jailbreak
- LLM Prompt Injection
- LLM Plugin Compromise
8) Defense Evasion :
Attackers aim to stay hidden from machine learning-based security systems like malware detectors.
- Evade ML Model
- LLM Prompt Injection
- LLM Jailbreak
9) Credential Access:
- Unsecured Credentials
10) Discovery :
Discovery involves methods that an attacker uses to learn about a system and its network.
- Discover ML Model Ontology
- Discover ML Model Family
- Discover ML Artifacts
- LLM Meta Prompt Extraction (LLM initial instructions)
11) Collection :
Adversaries aim to collect machine learning artifacts and related information that can help them achieve their goals
- ML Artifact Collection
- Data from Information Repositories
- Data from Local Systems
12) ML Attack Staging :
ML Attack Staging involves methods used by adversaries to set up their attack on the target machine learning model. These methods can include creating similar models for practice (proxy models), tampering with the target model’s data (poisoning), or designing misleading inputs (adversarial data) to deceive the target mode.
- Create Proxy ML Model
- Train Proxy via Gathered ML Artifacts
- Train Poxy via Replication
- Use Pre-Trained Model
- Backdoor ML Model
- Verify Attack
- Craft Adversarial Data
- White-Box Optimization
- Black-Box Optimization
- Black-Box Transfer
- Manual Modification
- Insert Backdoor Trigger
13) Exfiltration :
Exfiltration involves methods used by adversaries to extract data from your network. They might steal data for its valuable intellectual property or to use it in preparing for future attacks.
- Exfiltration via ML Inference API
- Infer Training Data Membership (Can lead to the unintended disclosure of private information)
- Invert ML Model
- Extract ML Model
- Exfiltration via Cyber Means
- LLM Meta Prompt Extraction
- LLM Data Leakage
14) Impact :
Impact refers to the actions taken by adversaries to interfere with or damage the normal functioning of a system.
- Evade ML Model
- Denial of ML Service
- Spamming ML System with Chaff Data
- Erode ML Model Integrity
- Cost Harvesting
- External Harms
- Financial Harm
- Reputational Harm
- Societal Harm
- User Harm
- ML Intellectual Property Theft